
Dans la même rubrique
Dans un texte critique riche, ample et pertinent, le sociologue Dominique Boullier, ancien coordonnateur scientifique du Médialab de Sciences Po, revient sur les enjeux de l’IA générative. L’auteur de Propagations. Un nouveau paradigme pour les sciences sociales (Armand Colin, 2023) et de Déshumanités numériques (Armand Colin, 2025) ne mâche pas ses mots pour décrire comment l’IA transforme notre rapport au monde. Tribune.
On croit encore souvent que la meilleure innovation gagne toujours. Dans de nombreux cas comme dans celui des LLM, c’est le contraire : la pire des IA est en train de gagner au point de s’imposer comme monopole radical au sens d’Illich. Monopole radical pour la classe vectorialiste dans la génération de code avec l’apparition de Claude Code, monopole radical pour le grand public dans les interactions à travers la diffusion des IA compagnons. Entre les deux, les usages professionnels restent toujours aussi incertains et ne fonctionnent qu’à la condition d’y injecter suffisamment de sémantique et de contrôle expert pour éviter des catastrophes industrielles.
Reconnaissons-le : toute expérience ordinaire d’interaction avec une IA générative se révèle toujours impressionnante et, lorsque les compétences augmentent, des outils encore plus bluffants sont désormais à disposition, comme l’ont expérimenté tous les utilisateurs de Open Claw, agrégateur d’agents. Et pourtant, dès que l’on veut réellement prendre en main ces outils, contrôler leurs opérations, les vérifier ou valider leurs résultats, les mêmes utilisateurs se retrouvent déçus, inquiets voire en colère, à moins d’adopter une tolérance inusitée dans l’univers des produits et services de ce type. [Précisons d’emblée que je n’évoquerai pas ici les éventuelles craintes à propos d’un futur d’IA générale souvent fantasmé mais seulement les constats issus des pratiques ordinaires.]
Ni science, ni industrie, ni éthique mais de l’ingénierie, de la finance et du buzz
Je résumerais cette ambivalence de cette façon, en termes d’éthos ou de posture : si l’on possède une culture, des principes et exigences à la fois scientifiques, industrielles et éthiques, on ne peut qu’être inquiet de voir l’emballement en faveur de ces IA fondées sur les LLM. A l’inverse, si l’on est fasciné par l’ingénierie, les performances financières et si l’on vit dans le monde du buzz permanent, l’IA produit une excitation inédite et sans cesse renouvelée malgré ou à cause des incertitudes qu’elle emporte avec elle.
Et l’on peut systématiser cette opposition terme à terme : science vs ingénierie, industrie vs finance, éthique vs buzz pour mesurer à quel point nous sommes en train de bifurquer, collectivement certes mais sous la houlette de quelques très grandes plateformes technologiques. L’époque moderne s’est caractérisée par la puissance d’une alliance entre science et industrie en y ajoutant depuis la seconde guerre mondiale, un contrôle moral progressif des finalités et des méthodes (la révision écologique principalement). Mais les LLM sortent totalement de cette trajectoire au profit d’un saut postmoderne radical fondé sur leur ingénierie toute-puissante, leur attractivité financière sans limites et leur capacité à générer du buzz, de l’alerte et de l’incertitude permanente.
On pourrait pourtant parier avec Yann Le Cun que ces LLM sont des impasses conceptuelles. On pourrait aussi considérer avec la plupart des grandes entreprises industrielles que les LLM n’offrent pas de fiabilité suffisante, ce qui explique leur adoption très réservée dans les process critiques notamment. On pourrait aussi soutenir avec quelques fondateurs du deep learning (Hinton, Bengio) que l’on risque trop de perdre le contrôle pour laisser se développer une telle technologie. Et pourtant, malgré toutes ces réserves, que je vais documenter et soutenir, ce sont bien ces LLM qui sont en train de former l’architecture technique d’un nouveau mode de production.
Quand les pires technologies sont pourtant les gagnantes
Car, rappelons-le , après des décennies de travaux sur les dynamiques de l’innovation, il est rare que la meilleure technologie gagne. Songeons au clavier Qwerty, cette machine de guerre ergonomique, encore présente dans nos PC, et même sur des smartphones tactiles. 150 ans de résistance à toute transformation malgré les tentatives nombreuses (cf. Dvorak) pour améliorer un système aussi nocif pour les muscles et aussi coûteux à apprendre. Sur ce plan d’ailleurs, les interfaces conversationnelles sont à elles seules une révolution durable qui va modifier la relation ordinaire à la technologie des systèmes d’information, plus encore que ne l’avait fait le Wysiwyg de la fin des années 70 qui a permis le Personal Computer.
De même, la domination de Windows sur tous les systèmes d’exploitation des PC (72% du marché) est le contre-exemple type opposable à l’argument selon lequel « le meilleur gagne ». Tout le monde le reconnaît, Windows a copié Apple (lui-même issu de Xerox) pour l’apparence de son interface, tout en reposant sur son système d’exploitation MS-DOS catastrophique en matière de fiabilité, de sécurité et de performances. Et pourtant, Microsoft l’a imposé au monde entier, grâce à des patchs successifs mais surtout grâce un marketing devenu un cas de figure canonique du « lock-in » (Shapiro et Varian), ce verrouillage d’une clientèle dans un système total. Dans le même temps, Linux (1991) est devenu incontournable pour tous les systèmes techniques critiques ou pour ceux qui exigent une véritable fiabilité mais c’est seulement en 2026 que le gouvernement français fait le choix d’abandonner Windows pour Linux pour les postes de travail de l’administration.
Un processus analogue se déroule ainsi sous nos yeux qui voit une innovation très approximative gagner des parts de marché et créer des habitudes d’usage quasi irréversibles. Les critiques pleuvent sur les systèmes d’IA génératives, sur leurs hallucinations d’abord, sur leurs consommations d’énergie ensuite, sur la collecte de leurs sources, sur leurs principes formels même, et cela sans parler des pratiques de certaines des firmes que j’ai qualifiées ailleurs de voyous (Open AI et X/ Grok) (Boullier, 3 février 2026 , AOC). Mais rien n’y fait, l’IA pénètre dans tous les interstices de la vie ordinaire plus vite que dans la vie professionnelle même, grâce à cette innovation horizontale, imitative, sans barrière d’accès (dont la gratuité, qui constitue un coup de force très convaincant pour les adopteurs). Quitte à avoir la pratique de l’IA honteuse, dans ce qu’on appelle la shadow AI, ces pratiques non déclarées au travail (Ferguson), dans les écoles ou à la maison. Processus d’innovation technique assez rare dans les organisations (Gaglio) qui ont souvent pratiqué plutôt le top-down en devant se battre plus contre les « résistances » des personnels que contre leur enthousiasme débridé et leur volonté de tout tester « pour voir » et finalement pour adopter.
L’heure du bilan n’a cependant pas sonné car tous les ans à peu près une nouvelle version ou couche d’innovation rebat les cartes, au point même de disqualifier les savoir-faire acquis, qu’on avait annoncé comme décisifs pour l’avenir (savoir prompter). Les agents sont déjà là, des systèmes comme Open Claw, même s’il est bridé désormais par Claude, permettent d’organiser des batteries d’agents en parallèle pour réaliser quantité de tâches ou de séquences de tâches, le vibe coding est mis à la disposition de tous, la production de vidéos (dont les deep fakes) est désormais opérationnelle pour des utilisateurs ordinaires. La seule limite constatée pour un certain niveau de performance reposait sur la compétition féroce pour les puces GPU de NVidia qui elles-mêmes changent de version souvent, mais désormais Google et Deep Seek utilisent leurs propres processeurs (TPU notamment) conçus spécialement pour leurs IA. Dans cette effervescence, la question du coût était restée jusqu’ici ignorée comme toujours avec la méthode classique du dealer de techno qui amorce les usages en offrant la gratuité, mais le coût des abonnements à ces services commence à augmenter sérieusement selon le nombre de tokens traités. Au point que l’optimisation de l’usage des tokens fait désormais partie des services de Anthropic, sous forme de « adaptative thinking », terme inadapté mais significatif de l’emphase qui caractérise ces firmes.
Disons-le franchement : j’espère quand même que cette hubris financière et technologique va conduire à une crise majeure, répétant la crise financière de 2008 car c’est sans doute la seule chance de rebattre les cartes et de rouvrir les possibles. Mais il faudra alors posséder cette boussole que je propose pour s’orienter radicalement différemment dans nos choix socio-techniques. A condition qu’il existe encore un espace politique démocratique pour passer à une « démocratie socio-technique » (Lascoumes, Callon, Barthe, 2001) pour inventer un autre avenir. Or, la domination des plateformes d’IA se fait désormais à l’échelle mondiale (Chine et USA) en étroite collaboration avec les régimes les plus autoritaires prêts à favoriser leurs monopoles en échange de services de surveillance omniprésents.
Au-delà des monopoles des plateformes IA, nous devons plus encore nous inquiéter d’un « monopole radical » de l’IA générative et des LLM sur les connaissances, pour utiliser les concepts d’Ivan Illich. Toute son analyse de la mobilité et de l’énergie (Energie et équité, 1975) montrait comment l’industrie pétrolière avait installé un monopole radical de l’automobile supposée solution unique pour traiter nos demandes de mobilité. Alors même que le calcul de la vitesse généralisée (Dupuy, Robert) montrait qu’en intégrant tous les coûts de production et d’utilisation d’une voiture, sa performance en termes de vitesse devenait inférieure à celle d’un vélo. J’expliquerai dans un livre à venir pourquoi la comparaison des LLM avec le coup de force du moteur à explosion et de l’automobile est la plus pertinente en matière de monopole radical, entraînant toutes les dérives sociales, urbaines et environnementales que l’on connaît. C’est pourtant l’avenir qui nous attend dès lors qu’on laisse les entreprises d’IA le façonner pour nous.
Reprenons chacun des dyptiques proposés pour comprendre comment une ambivalence attraction/répulsion finit pourtant par engendrer ce monopole radical.
1/ Absence de science mais ingénierie géniale
J’ai conscience de surprendre ainsi beaucoup de chercheurs qui travaillent sur l’IA et sur certains principes qui ont guidé tout ce courant de recherche, souvent fondé sur des mathématiques de haut niveau. Certains n’accepteront pas de voir disqualifier leurs prétentions scientifiques. Précisons que ce n’est pas parce qu’on dispose de disciplines, de revues et de postes académiques qu’on fait de la science (nous autres chercheurs en sciences humaines et sociales sommes quotidiennement disqualifiés pour cela précisément). L’ingénierie est une activité très noble qui mobilise des rapports parfois étroits avec la science, de même que la médecine, mais ni l’une ni l’autre ne sont des sciences mais plutôt des sciences appliquées, dit-on parfois, et surtout des arts. Le soin est un art plus qu’une science malgré toutes les tentatives de « evidence-based medecine » qui autoriserait les transferts de décision à des systèmes d’IA, au prix d’une ignorance de ce que la relation de soin et la maladie possèdent de multidimensionnel. L’ingénierie, de ce point de vue, peut être géniale et on ne le contestera pas, depuis Léonard de Vinci au moins ! Mais c’est son art de l’assemblage de connaissances, plus ou moins modélisées, dans la résolution d’un problème opérationnel qui produit l’émerveillement. Il faut que ça marche, voilà l’impératif. Or, les observations in situ sur le travail des ingénieurs, comme celles effectuées par les STS et tout le courant de l’ANT (théorie de l’acteur-réseau, Vinck), ont bien montré que quantité de décisions opérationnelles relèvent du pari, de l’opportunité et surtout du tissage d’un réseau multidimensionnel pouvant mobiliser des compétences et des ressources extrêmement diverses. C’est le cas avec les LLM et avec l’IA générative.
Quand l’absence de théorie du langage est productive pour l’ingénierie
En effet, zéro science dans ces IA et on pourrait même dire que c’est grâce à cela que ça marche. C’est ce que disait ce CEO d’une firme de NLP (traitement automatique du langage naturel) il y a plus de quinze ans qui affirmait avec provocation que les performances de ses modèles s’amélioraient à chaque fois qu’il virait un linguiste. Et en effet, les LLM n’ont aucune théorie du langage et se débrouillent très bien pour éviter d’en avoir une, puisqu’ils reposent sur une tokenisation et une vectorisation de tout le matériel linguistique, qui n’a strictement rien à voir avec une analyse du langage, structurale ou même générative à la Chomsky. Le texte fondateur des « Transformers » publié par Google en 2017, l’annonçait d’ailleurs explicitement : « All you need is attention ». Ce qui veut dire en clair que dès lors que l’on veut détecter des patterns, des régularités dans des corpus linguistiques pour prédire les segments suivants, tout ce qui compte c’est la fenêtre de mémoire disponible au moment de l’entraînement sur des corpus par ailleurs toujours plus énormes, de façon à réduire les erreurs. Pas de théorie, pas de concepts, seulement un exploit technique réductionniste à l’extrême et pour cette raison très opérationnel, qui permet de traiter tout token dans un espace latent vectorisé pour pondérer ses probabilités de combinaison et donc d’apparition dans un « contexte » toujours plus grand, cette fenêtre d’attention. Evidemment, l’astuce technique, élémentariste comme toute l’informatique depuis Turing, nécessite des capacités de calcul rarement disponibles, surtout dans un laboratoire académique, et des capacités de collecte de données d’entraînement qui s’affranchissent des règles académiques de sourcing ou de droits d’auteurs (nous verrons cela plus loin dans le chapitre moral).
Cependant, reconnaissons que les résultats de cette simulation de production linguistique à partir de ces matériaux et de ces « astuces » techniques sont prodigieux pour un observateur neutre ou même critique. J’ai moi-même, il y a bien longtemps, développé des chatbots et des méthodes d’ingénierie linguistique en milieu industriel puis académique et la performance ne m’échappe pas. Mais je sais aussi par expérience, tout ce qui a été nécessaire de bricolage, de patch, de tâches aveugles, et de risques pris pour faire tenir un système technique après quantité d’arbitrage faits souvent à la volée et sans justification et sans vérification possible de leurs conséquences sur tout le système. Expliciter tout cela serait considéré comme indécent pour un utilisateur lambda dont on veut par ailleurs faire un utilisateur convaincu et capté dès la première requête puisque l’adoption fonctionne désormais dans l’instant (et non à la décision éclairée).
La boite noire n’est jamais acceptable dans une visée scientifique
Pourtant, cet effet boîte noire reste totalement antinomique avec des exigences scientifiques. Car adopter une visée scientifique (Gagnepain), c’est s’obliger à contester méthodiquement ses propres énoncés pour les vérifier, les discuter dans une communauté de pairs, ce qui suppose de les publier pour pouvoir les répliquer et ensuite les réviser. La chaîne de la référence (Latour) est très longue et doit être explicite. Ce qui n’a rien à voir avec les méthodes de production de l’IA générative qui fonctionne aux résultats simulés et produits en toute opacité. On se trouve alors plus proche de la visée mythique qui doit nous faire croire aux résultats par une simulation merveilleuse et ces IA génératives produisent en effet des merveilles.
Et lorsque les LLM se soumettent à une vérification, c’est à travers des benchmarks et non des expériences réplicables qui permettraient de suivre toutes les pondérations faites automatiquement, ou les méthodes d’apprentissage supervisé et de constitution d’une ground truth (« vérité de terrain », Jaton), qui posent tant de problèmes éthiques occultés. Aucun process explicite donc, contrairement au mouvement existant depuis plus de dix ans d’ « explainable AI » car depuis l’IA connexionniste, dans sa version réseaux de neurones puis deep learning, on sait qu’il n’est plus possible de vérifier tous ces processus, même quand on en est le concepteur. La démarche scientifique ne peut en aucun cas se satisfaire de ces boîtes noires puisque toute la construction des énoncés qui font science a reposé depuis des siècles sur des communications de protocoles et de résultats permettant une éventuelle réplication. Exigence qui se perd, il est vrai, même dans les sciences dures soumises elles aussi au culte du « résultat-positif-à-diffuser » pour améliorer ses scores de publication. On peut se dire alors que le ver était dans le fruit, et que tous les impératifs de publication délirants désormais exigés par les politiques publiques de recherche n’ont pas attendu l’IA pour dégénérer.
L’espace latent probabiliste ne peut pas produire une ontologie
Plus spécifiquement il faut noter la déstructuration délibérée de toute l’articulation du langage, de cette combinatoire analytique de son et de sens, productrice d’un potentiel infini d’expressions. Avec les LLM, il ne s’agit plus que de découpages de matériel langagier écrit optimisés pour leur calculabilité : tout peut devenir token, jusqu’à des signes de ponctuation, sans rapport avec le sens ni avec l’expression orale par ailleurs. Les relations ou vecteurs ne sont plus structurées (pas de lexique, de champ sémantique, de lemmes, de phonèmes, etc… tous articulés entre eux) mais seulement pondérées par leur fréquence d’apparition commune dans un corpus donné.
Sur ce plan, il faut veiller à ne pas confondre l’ingénierie linguistique qui était réalisée au temps du Machine Learning. Si l’objectif de calculer les distances entre entités linguistiques d’un corpus peut sembler voisin de ce qui est actuellement pratiqué par les LLM, ce serait oublier la torsion complète de ces principes par les LLM. Car à cette époque, les entités calculées étaient encore des lemmes, issus d’une racine qu’on pouvait organiser en relations sémantiques via des flexions, syntagmes et variations de tous types, au-delà des simples cooccurrences dans un même environnement. Les corpus étaient eux-mêmes limités car thématiques, présélectionnés ou identifiables par leurs origines. Désormais on parle de tokens qui décomposent tout matériel graphique (et non verbal) en élément dont on va estimer la fréquence d’apparition dans un corpus infini, non indexé ni identifiable (effet boite noire). Un token n’a plus besoin de relation sémantique avec son environnement, seulement sa co-occurrence statistique suffit à produire un vecteur qui sera pondéré (et désormais non révisable puisque tout se passe dans l’opacité la plus totale).
C’est ici qu’une coupure avec la sémantique s’est introduite définitivement dans la méthode même de décomposition par token et de vectorisation. Le coup de force des LLM tient au fait qu’ils prétendent traiter toute une langue, grâce à une collecte d’un corpus infini, ce que leur permet en effet leur prédation systématique de tous les contenus disponibles. Tout ce traitement s’effectue dans une langue donnée, qu’on doit ensuite traduire dans d’autres langues qui n’auraient pas les corpus suffisants, d’où d’autres distorsions introduites dans ce corpus supposé universel.
La puissance statistique de ces probabilités reposant sur des corpus toujours plus vastes leur permet de simuler en effet des effets de langue très plausibles et de masquer totalement leur absence totale de sémantique, de référence au monde perçu, et d’attributions de valeur systémique aux relations/vecteurs calculés. Il s’agit bien d’un artifice d’ingénierie tout-à-fait prodigieux dans ses résultats, même s’il a la particularité d’être totalement incontrôlable ou inauditable dès lors que l’espace latent où tout se calcule n’a plus aucune relation avec le sens et combine tellement de dimensions que personne ne peut plus rendre compte des pondérations effectuées (the curse of dimensionality, Bellman, 1957). L’opacité du système est le prix à payer pour sa performance.
Le maquillage sémantique indispensable pour sauver le soldat LLM à tout prix
Cependant, ses faiblesses structurelles d’accès au sens engendrent tant d’erreurs qu’il faut là encore mobiliser des correctifs sans cesse plus ingénieux mais qui demeurent des expédients. C’est ce que l’on a nommé au début des LLM des « hallucinations », en fait des erreurs, des inventions de toutes pièces et sans aucun sens, présentées de plus sans aucune précaution sur les limites du système et sur le principe même des probabilités. L’obligation de réponse à tout prix, qui n’a rien à voir avec une exigence scientifique ni avec une garantie industrielle (voir chapitre suivant), relève en fait de la promesse commerciale et de la captation de dépendance d’un public sans aucun recul critique.
Pour réduire ces effets pervers – mais en fait constitutifs même des choix techniques d’ingénierie effectués contre toute exigence scientifique -, un certain nombre de méthodes sont employées pour réintroduire par la bande de la sémantique que l’on a exclue au départ pour optimiser la vectorisation généralisée des contenus d’entraînement. Ainsi, tout le travail d’annotation réalisé par les travailleurs du clic et les petites mains des plateformes (Casilli, 2019) sert avant tout à cela : produire une supervision de départ qui ne dit pas son nom mais qui permet de générer une ground truth qui limitera les dégâts, ce que Mechanical Turk d’Amazon offre comme service par exemple. C’est pourquoi le travail précaire et sous-payé de tout ce nouveau prolétariat des pays du sud, plus proche du péonage que du salariat (Moulier-Boutang), ne peut être occulté comme fondation sémantique des systèmes d’IA génératives. Certes, les modèles auto-apprennent ensuite, mais un contrôle reste nécessaire pour éviter de voir la qualité se dégrader de façon trop visible. Aucune science dans cette affaire, seulement la reconnaissance par l’ingénierie des patchs nécessaires pour corriger les défauts des choix initiaux. En l’occurrence, « attention is NOT all you need », il faut aussi celle d’humains enchainés à leurs écrans et à leurs micro tâches qu’on ne saurait montrer ni reconnaître.
De même, en raison de la spécificité sémantique de la plupart des domaines professionnels, avec ces LLM, il reste quasiment impossible d’assister correctement des processus de décision ou de création de contenus lorsque les documents sources sont noyés dans le corpus général des modèles centralisés. Il faut réintroduire du « contexte » dit-on parfois de façon erronée alors qu’il s’agit en fait de réintroduire du sens, articulé en sémantique, avec des termes spécifiques organisés en ontologies comme on le fait toujours avec l’IA symbolique. Tout process industriel qui ne se fonderait pas sur ces bases robustes courrait à la catastrophe.
Patches en tous genres : RAG, Chains of Thought, MCP
Mais là encore, l’ingénierie des firmes de l’IA se débrouille pour vanter l’intervention des experts du domaine sur des modèles réduits de LLM que seront les RAG (Retrieval Augmented Generation). Les experts d’un domaine injectent leurs contenus contrôlés, validés et pertinents pour leur secteur dans les données d’apprentissage du modèle général ou dans une version plus locale et restreinte, et réduisent ainsi considérablement les risques de non-pertinence ou d’erreurs. On entraîne ainsi le modèle sur des corpus de documents administratifs ou techniques issus de l’entreprise ou de l’administration et on s’assure ainsi qu’il effectuera les tâches demandées avec plus de fiabilité. Comme on le voit, il s’agit là encore d’une astuce d’ingénierie qui ne corrige en rien les défauts structurels des LLM mais qui réduit leur impact dès lors qu’il existe des experts capables d’alimenter les corpus d’apprentissage en contenu contrôlé. Il faut donc à nouveau des humains qui réintroduisent de la sémantique pour obtenir des résultats fiables. Pourtant, tout cela est présenté comme un additif normal et ingénieux aux LLM et non comme reconnaissance d’une faille constitutive de leur architecture stupidement probabiliste.
Un autre patch consiste à équiper ces systèmes d’IA générative à base de LLM de « chaînes de pensée » (Chain of Thought) leur permettant de construire un raisonnement en décomposant un problème en séquences. Le terme de « pensée » peut être trompeur car il ne s’agit que d’étendre les capacités élémentaires de tout système informatique à décomposer en procédures et en séquence opérationnelle toute résolution de problèmes, ce qui est au fond à la base de toute compétence technique. Fournir cette capacité n’a rien d’un raisonnement. Alors qu’il existe des systèmes d’IA effectivement raisonnante, mais de type symbolique et totalement explicable, comme Xtractis, produit par Intellitech (Zalila). Dans ce cas, toutes les pondérations et décisions sont traçables car elles sont fondées sur de solides armatures logiques que toutes les IA symboliques mobilisent depuis des décennies.
Dernier épisode en date de la même opération de sauvetage des systèmes d’IA génératives asémantiques : le passage à l’IA agentique, capable d’effectuer des tâches de commande, de gestion, faites de séquences complexes et adaptées aux infinies variations du monde réel. On comprend bien le défi. Des systèmes automatisés, ne disposant d’aucune représentation significative du monde mais seulement d’une capacité infinie de pondération des vecteurs linguistiques pour engendrer des prédictions, se trouveront en difficulté face à la complexité du monde réel, et aux ambiguïtés sans fin de toute langue et de toute situation. Une astuce supplémentaire de l’ingénierie des entreprises d’IA permet de simuler une réduction de ces aléas. On dispose désormais en effet d’un protocole pour harmoniser la description du monde : serait- ce une ontologie ? Certes non, seulement une simulation limitée au monde des interactions entre machines : le MCP, Model Context Protocol, se contente de standardiser les API que devront utiliser les systèmes d’IA pour devenir vraiment des agents « dans le monde », en fait des agents bien limités au monde des systèmes d’information normalisés pour devenir interopérables par des IA agentiques. Une nouvelle fois, la question du rapport au monde, de la sémantique nécessaire pour en construire la représentation est évacuée par une opération d’ingénierie. Cela permet cependant de construire ainsi un début de standardisation du secteur, ce qui est industriellement non négligeable.
Mais il en sera autrement dans les secteurs industriels critiques comme nous le verrons. Lorsqu’on voit que Palantir, dans sa fourniture de systèmes de décisions de frappes militaires létales, présente explicitement la couche d’ontologies qu’elle ajoute aux LLM qu’elle utilise, en parlant d’une nomenclature pré-encodée (c’est-à-dire contrôlée et validée par les humains selon un schéma cohérent sémantiquement), on comprend mieux ce qui se déroule et se déroulera dans les autres industries, qui ont des exigences encore plus sévères que dans les industries de défense dont la précision n’est pas l’impératif prioritaire, comme on l’a constaté récemment. Les benchmarks récents pour tester ces systèmes d’agents ont cependant produit des résultats très inquiétants quant à leur fiabilité et à leur sécurité (Shapira et al., 2026).
La mutation du mode de production du code, étape essentielle vers le monopole radical
Il faut cependant admettre que les limites asémantiques des LLM ont été particulièrement bien exploitées pour la production du code informatique. Ce qui peut se comprendre aisément, puisque précisément le code n’est pas le langage ni la langue et que son univocité le rend opérationnel sans risque de contre-sens comme on dit, puisqu’il ne s’agit plus de sens mais de commande pour l’action. Cette réduction du langage des propositions logiques au code du programme fut la force du pari initial de Turing (Lassègue et Longo, 2025) qui continue d’être exploité. La production de code entraîne pourtant des erreurs nombreuses variables selon les systèmes d’IA mais désormais bien réduites avec l’avancée apportée par Claude Code. On mesure alors la productivité potentielle d’une telle performance d’ingénierie puisque ces systèmes peuvent générer du code pour générer du code pour générer du code, à plusieurs niveaux. Cela a entraîné la fascination des milieux des développeurs pour Open Claw qui génère, lui, des agents organisés en système dans des délais d’une rapidité inouïe par rapport aux tâches séquentielles précédentes.
C’est ainsi dans ce domaine du code que les LLM sont en train de modifier le mode de production informatique en général et de ce fait d’un grand nombre de process industriels. De l’autre côté, pour le grand public, c’est la mutation des compagnons à travers des interfaces conversationnelles performantes qui est en train de s’installer comme routine ou comme évidence dans la vie quotidienne. Notre mode de production des interactions quotidiennes va s’en trouver clairement affecté radicalement. Le problème, dans les deux cas, industrie ou interaction, tient à l’absence totale de traçabilité et d’explicabilité de tous ces systèmes, si performants et si opaques à la fois. Les erreurs, bugs ou hallucinations sont inévitables et l’expertise pour les détecter aura tendance à se raréfier puisque seules des IA pourront éventuellement réauditer de telles boîtes noires. Et lorsqu’on se réjouit de voir que Claude a détecté avec Mythos des bugs jusqu’ici ignorés qui sont en fait de vraies failles de sécurité, on accepte d’ignorer que l’on ne sait pas si ces failles étaient vraiment critiques (d’où le peu d’intérêt pour les détecter avant), quelle est la proportion de bugs existants non détectés par l’IA (par définition !), et si l’IA ne détectera pas de faux bugs (faux positifs) que personne ne saurait contredire (Schneier, 2026). Il faut donc accepter les miracles et continuer à avancer à l’aveugle.
Mais plus on s’oriente vers cette transformation en profondeur du mode de production, plus cela tend à réduire les LLM à des systèmes d’exploitation, dont nous ne connaissons toujours pas les applications adaptées à DES environnements toujours spécifiques. Or, dès qu’on veut implémenter une application robuste dans le vrai monde, il faut y rajouter une couche sémantique. Certains plaidaient depuis longtemps pour cette hybridation symbolique/ génératif mais le débat porte rarement explicitement sur cela : on se contente de patchs sémantiques ( et donc à base d’IA symbolique) dès qu’on veut installer des process fiables. Nous pourrions donc évoluer ainsi vers un équivalent de MS-DOS. On interagit avec un Windows qui est en fait une copie de Mac OS, pertinente et conviviale, mais toujours plaquée sur un OS antique et inadapté, ce qui a duré pendant 40 ans environ. Par analogie, nous accepterions donc les défauts intrinsèques de ces LLM en acceptant de les corriger sans cesse, de les camoufler pour éviter d’interroger la nullité scientifique des LLM. Alors qu’il serait possible de concevoir dès maintenant une IA hybride dans son cœur même, en s’appuyant sur les IA symboliques raisonnantes déjà disponibles pour leur ajouter quand c’est nécessaire les capacités génératives issues des méthodes des LLM. Mais tout cela sans développer toute l’usine à gaz énorme que sont les data centers et la collecte en masse de données pour l’apprentissage. Philosophie totalement différente mais qui ne gagnera pas forcément comme je l’explique dans la seconde partie sur l’industrie. Pourtant, d’autres acteurs tentent d’explorer une sortie de cette impasse.
En sortir par une extension de l’automatisation avec les « modèles du monde » ?
En effet, peut-être devrait-on confier notre sort à ceux qui, comme Yann Le Cun, nous fixent des objectifs de pertinence nettement plus robustes en sortant des limites des LLM. On peut comprendre l’ambition de ne plus faire reposer les modèles sur du matériel uniquement linguistique, même si cela pouvait fonctionner assez aisément pour des visées de génération de contenus. L’idée de descendre au niveau de la perception et d’entraîner désormais ces systèmes sur des vidéos qui démultiplient les indices en les situant dans des univers réalistes qui fournissent une connexion de fait avec le monde (même si médiées par le support vidéo) paraît ambitieuse en termes de capacités de calcul et de temps d’entrainement mais cohérente pour dépasser les limites des LLM. En réalité, malheureusement, il s’agit là encore d’une ingénierie magnifique et prometteuse, mais qui échoue à caractériser scientifiquement ce qu’est l’expérience du monde du point de vue cognitif et qui de plus ne fournit comme horizon industriel et moral qu’une automatisation toujours étendue.
L’expérience du monde n’est pas faite seulement des inputs de signaux très riches fournis par nos sens. En premier lieu, elle est construite dans une boucle qui suppose une interaction effective avec le monde : les gestes, les actes doivent être éprouvés et avoir un effet sensoriel au-delà de leur visionnage sur un écran de vidéo pour pouvoir constituer une base d’apprentissage robuste. Cela nécessiterait alors de doter ces systèmes d’IA d’un équivalent de corps, et donc de pousser l’automatisation encore plus loin vers une robotique étendue et sans limite a priori. Cependant, le principal manque de la vision des « modèles du monde » de Le Cun, c’est la dimension collective de l’apprentissage du monde, ne serait-ce qu’à travers le regard d’un autre humain, souvent un parent nourricier. Ce couplage étroit, plus ou moins satisfaisant mais déterminant pour le psychisme, semble demeurer extérieur aux modèles du monde. Or, l’expérience du monde est intersubjective par définition ou même distribuée car on doit penser en termes de « cognition distribuée » (avec des humains et des non-humains) (Hutchins). On n’inventera pas une compréhension du monde qui ne soit fondamentalement dialogique, et donc psycho-sociologique.
On pourrait alors prolonger juste un peu plus loin la saga de l’ingénierie de l’IA et annoncer : « qu’à cela ne tienne, nous allons modéliser aussi tous les comportements psychosociologiques et nous aurons ainsi atteint le but ultime de l’IA générale, totalement équipée des compétences humaines ». Voilà où la question morale revient en force, avec cette tendance lourde de la classe vectorialiste à s’en passer allègrement. Pour rester pertinente, l’IA la plus enrichie socialement doit se fonder sur une théorie de la technique qui sorte du fantasme de simulation totale et d’automatisation sans limite. La technique est une compétence humaine qui se combine sans cesse avec les autres compétences inhérentes à la condition humaine et ne peut jamais être désencastrée des rapports sociaux, politiques, désirants, émotionnels qui obligent de ce fait à inclure les humains dans la boucle. Ils le sont comme experts en premier lieu pour la valeur indicielle irremplaçable de leurs connaissances mais aussi et surtout comme sujets de désirs et de droits et comme collectifs coopératifs. Une IA qui s’affranchirait de toute connaissance et de toute théorie de toutes les compétences humaines pour remettre la technique à sa place serait en fait atteinte d’hubris et profondément dangereuse. C’est ce que certains prophètes proclament d’ailleurs, un peu vite et avec des arguments tordus parfois, pour à la fois réduire la vitesse et l’accélérer pour aboutir à l’étape suivante de l’automatisation totale plus rapidement.
Pourtant, il reste possible de faire bifurquer ce train lancé à toute vitesse et qui semble inarrêtable sur cette voie unique, celle des LLM fournie par les plateformes. Pour cela, il convient de sortir de la fascination pour l’ingénierie en exigeant de réintroduire des impératifs scientifiques et donc une exigence de compte-rendu explicite de tous ces systèmes, une auditabilité que les impératifs industriels avaient pourtant installé comme convention sociale bénéfique à tous. Comment se fait-il que non seulement les LLM peuvent se passer des impératifs scientifiques mais aussi des impératifs industriels ?
2/ Abandon des impératifs industriels, triomphe des performances financières
Les prouesses d’ingénierie que l’on vient de souligner devraient normalement entraîner des qualités industrielles équivalentes si l’on vivait encore dans le capitalisme industriel. Or, n’oublions jamais que c’est désormais un régime de capitalisme financier qui nous gouverne (Orléan, 2011). Le secteur du numérique est totalement dépendant des principes, des méthodes et des puissances fournies par la finance qui adore l’IA, quand bien même les performances industrielles de ces systèmes d’IA sont à proprement parler catastrophiques. C’est ce paradoxe qui doit être pensé pour comprendre à quel point nous allons dans le mur en tant que société dite « moderne » en confiant notre avenir à ces systèmes d’IA. La domination financière sur l’allocation de ressources accélère encore ce processus malgré l’inconséquence industrielle qui la sous-tend.
Les qualités industrielles attendues des systèmes d’IA devraient être de deux types : une fiabilité la plus élevée possible, à défaut de totale qui serait un fantasme (Gérard Berry), et une architecture efficiente, c’est-à-dire la plus économe possible de toutes ses ressources. Il ne suffit plus de faire preuve d’ingéniosité pour obtenir le meilleur résultat possible une fois : dans un système industriel, il faut pouvoir assurer la répétition, le passage à l’échelle, la maintenance, et la fiabilité dans des circonstances totalement différentes. Or, aucun des LLM sur le marché ne peut assurer cela et d’autant moins que ce sont des systèmes opaques non réglables avec précision, contrairement à ce qu’on prétend faire avec du fine-tuning (qui revient en fait à réinjecter de l’expertise humaine et donc de la sémantique au cas par cas, ce qui n’a rien d’industriel précisément).
L’étrange acceptation de l’absence de fiabilité industrielle des LLM
Lorsque l’utilisateur ordinaire constate des hallucinations ou des réponses trop évasives, trop bavardes ou incompréhensibles de systèmes d’IA conversationnelles qu’il utilise, il s’agit souvent de situations individuelles, de communication, sans grandes conséquences, avec de plus une propension des utilisateurs à s’auto-incriminer pour leur incapacité à faire les prompts corrects tant le mythe de « l’intelligence » de la machine finit par s’imposer. Cette tolérance n’a rien à voir avec celle qu’on peut avoir aussi dans l’industrie pour des systèmes de production et de services qui doivent assurer une qualité permanente du produit et une traçabilité très exigeante. Comment se fait-il d’ailleurs qu’on n’exige jamais de la part des plateformes d’IA génératives des démarches qualité, des audits et de la documentation comme on le fait dans tout secteur industriel ? Car tous les secteurs sont soumis à des réglementations, à des standards, à des responsabilités légales et pénales dans les cas de non-respect de normes, de procédures ou de contrôles. Ce fut tout du moins tout l’effort des années après-guerre où l’industrie se trouva régulée par les Etats ou par ses propres conventions entre concurrents.
Rien de tout cela dans les firmes de l’IA qui se sont totalement affranchies des exigences devenues communes dans l’industrie. On peut arguer que le secteur étant en construction, il faudrait attendre un peu avant que cela se stabilise. Or, la pénétration de l’IA dans tous les secteurs, ou tout au moins les efforts des vendeurs d’IA dans ce sens, exige que les processus IA soient soumis aux mêmes degrés d’exigence que tous les autres composants d’un secteur donné qui peut aller de la comptabilité à la logistique en passant par les matières premières, les machines, etc. et cela pour les produits, les process et les personnes, les 3P de toute démarche qualité. Cette façon désinvolte de disqualifier les procédures industrielles au nom de la disruption éclair est très choquante pour ceux qui connaissent cet univers. Aucune autre industrie ne pourrait s’autoriser une fiabilité aussi faible, fut-ce au bénéfice de l’accélération et du gain de temps supposé. Certes, certains secteurs critiques parviennent à exploiter des briques de LLM pour amplifier les performances de leur activité de façon limitée et à condition d’y rajouter leurs propres données validées comme pour le RAG ou une couche de sémantique comme je l’ai indiqué. Mais cela indique bien l’absence de fiabilité intrinsèque de ces LLM et le surcoût induit par la nécessaire intervention des experts dans la boucle, ce qui invalide la promesse fantasmée des vendeurs de LLM.
L’un des moyens classiques de l’industrie pour pousser à l’augmentation de la qualité et rétablir les conditions de la concurrence plus équitables a toujours reposé sur la standardisation, sur la production de normes (et non seulement de la part des Etats contrairement au roman libéral anti-bureaucratique qu’on nous sert en permanence). En effet, la compatibilité entre produits et services et la comparabilité des performances et des qualités servent la stabilisation des marchés, et donc la viabilité d’investissements de long terme comme l’exige tout appareil de production tangible. Il semble que, en l’absence de cet aspect tangible puisque le numérique est éminemment plastique, même s’il n’est en rien immatériel, ce secteur puisse s’affranchir de cet impératif d’organisation du marché.
La disparition de la culture des tests
L’un des indices de cette compétition sans règle industrielle peut être observé dans la disparition de la culture des tests. Dès lors qu’il n’existe plus de normes ni de standards, pourquoi se préoccuper d’étalonner avec des mesures fiables ses propres produits et services ? A défaut de ces normes, on pourrait penser que ces tests seraient cependant utiles pour anticiper la satisfaction du client et éviter des retours consommateurs parfois destructeurs de réputation. Et pourtant non, les nouveaux entrants sur le secteur de l’IA générative, comme Open AI, ont au contraire tout fait pour court-circuiter les entreprises en place, soucieuses de leur réputation, et ont mis sur le marché des systèmes non validés, sans fiabilité aucune, à charge aux utilisateurs adopteurs précoces de faire remonter leurs retours et d’attendre la nouvelle version.
Ce principe du chantier du code qui court (le rough consensus and running code de J.P. Barlow) qui se corrige de lui-même constitue une rupture avec les impératifs industriels qui ont mis du temps à s’installer durant tout le XXe siècle mais qui ont produit des systèmes techniques plutôt fiables et de moins en moins insécures, avec l’appui des réglementations étatiques contraignantes dans certains domaines, il faut bien le dire. Le seul étalonnage des systèmes d’IA disponible en public reste donc les benchmarks effectués soit par les universitaires soit par des cabinets, à intervalles très fréquents puisque les versions se succèdent sans cesse, ce qui permet d’ailleurs de disqualifier les benchmarks dont les remarques critiques ont été déjà corrigées dans des versions nouvelles sorties quasiment avant la publication critique.
Les tests de validation du code existent toujours cependant. Mais ils permettent seulement d’éviter les principales erreurs mais non de relever ou de comprendre les décisions effectuées. Pire encore, la rapidité de génération du code est désormais telle que les générations de seniors chargées de l’auditer n’ont plus le temps de le faire. Cela renforce ce qu’on appelle désormais même chez les développeurs une « dette cognitive », c’est-à-dire une perte de compétence pour interpréter le code que l’IA permet de générer. Et Anthropic a vérifié son augmentation dans les dernières versions qu’il appelle « the compréhension debt » (Osmani, 2026) : « AI generates code far faster than humans can evaluate it ».
Ces benchmarks ont-ils un rapport avec l’expérimentation scientifique ? En rien. Avec les tests normalisés des industries classiques ? En rien ! Avec les tests ergonomiques ou fonctionnels pour anticiper la qualité de services et l’acceptation par les utilisateurs ? En rien. Ce sont en fait des repères flous et instables pour s’orienter dans une compétition d’opinion sans aucun référent industriel stable qui rendrait ces systèmes commensurables. Et pourtant des décisions majeures sont prises dans les boards et les gouvernements sur la base de ces appréciations qui créent la rumeur, qui disqualifient sans démonstration sérieuse ou qui vantent des performances jamais comparables. L’effondrement d’un sens pratique de la mesure et de son rôle régulateur n’est pas le moindre des paradoxes de cette emprise de la finance sur un secteur productif qui rend le travail des régulateurs particulièrement difficile.
La réglementation européenne récente prend acte de ces risques en matière de fiabilité mais limite les exigences de haut niveau aux systèmes les plus critiques, à risque, alors qu’on ne peut jamais savoir a priori les conséquences d’une absence de fiabilité et de traçabilité. Les exigences d’auditabilité sont quasiment inapplicables par définition à ce degré de complexité lorsque tant de couches de neurones sont concernées. La seule prétention à une amélioration de cette fiabilité repose sur l’augmentation permanente des données, leur renouvellement, leur mise à jour et l’augmentation des performances probables dans l’espace latent de ces vecteurs totalement incontrôlables.
Le culte de la brute force et de la taille si séduisantes pour la finance
On comprend mieux dès lors la course à l’installation de gigantesques centres de données partout dans le monde, conçus comme la base stratégique d’une robustesse industrielle. Or, cette dépendance à la taille des centres de données indique avant tout la faillite industrielle du modèle des LLM, leur efficience ne faisant que diminuer pour maintenir la croissance de leur efficacité. Toujours plus gros devient la seule solution pour réduire l’absence de fiabilité. La demande de vitesse des réponses et des calculs ajoute encore à cette exigence mais on perçoit alors à quel point les performances d’ingénierie sont obtenues au prix d’un gâchis industriel invraisemblable. On sait que les effets d’échelle peuvent jouer un rôle dans certaines industries pour augmenter la fiabilité dès lors qu’on peut réaliser des investissements conséquents pour effectuer tous les contrôles nécessaires et obtenir une standardisation plus avancée. A la condition d’avoir des procédures, des dispositifs de contrôle et de pilotage fin et des métriques permettant de rendre compte de ces améliorations et de détecter en continu les baisses de qualité en faisant par exemple de la maintenance préventive.
Mais rien de tout cela dans les centres de données qui sont nécessaires à l’augmentation de puissance des systèmes d’IA, non pour leur fonctionnement technique opérationnel au quotidien (les serveurs doivent fonctionner correctement !) mais pour leurs performances sur leur service de base. Cette culture de la taille, cette course à la masse de données, constituent sans doute les faiblesses principales du modèle extractiviste du modernisme industriel, du point de vue même de la performance industrielle, comme on l’a vu avec les conséquences de la dépendance au pétrole. Et pourtant, c’est ce qui est réactivé avec les centres de données surdimensionnés qu’on installe désormais uniquement pour tenter de réduire les insuffisances intrinsèques de modèles de langue purement statistiques.
La corruption financière de toute exigence de qualité industrielle
On ne peut comprendre cette carence de qualité industrielle si l’on n’inscrit pas le secteur de l’IA générative (et tout le numérique avec elle) dans une économie financiarisée. En effet, les investissements exigés pour ces centres de données, leurs puces, leurs ressources énergétiques, semblent totalement décorrélés de leur efficience industrielle, d’un bilan comptable sérieux, d’un équilibre entre investissements et retours sur investissements. Car les liquidités pleuvent sur ce secteur (et les Etats abondent, qui plus est : 500 milliards de Trump, 100 Milliards de Macron, etc. !) seulement en raison de la promesse spéculative que les plateformes d’IA soulèvent, sans aucun égard pour la rationalité industrielle et comptable d’un bilan d’une entreprise ordinaire. Nous avons quitté non seulement les critères de gestion d’un « bon père de famille » comme on disait autrefois mais aussi ceux de la gestion prudente d’une entreprise quelconque, et même celle de la gestion d’une trajectoire innovante à risque, qui suppose malgré tout quelques garanties.
Pour continuer à entretenir le narratif attracteur d’investisseurs, les firmes comme Open AI sont capables d’effectuer des montages financiers tout aussi opaques que leurs algorithmes, à travers des prises de participation croisées avec Nvidia par exemple indexés sur des promesses d’achat de puces, le tout sans aucune garantie, sans traçabilité comme on sait très bien le faire dans la finance. Le but est ici de faire des effets d’annonce en permanence (d’où l’importance du buzz que nous traiterons dans la troisième partie) pour maintenir en vie la promesse de monopole qui attire avant tout les investisseurs (parier sur le gagnant final comme ce fut le cas pour Amazon) et qui constitue le B A BA de l’idéologie libertarienne professée par Peter Thiel. Le capitalisme financier n’a que faire de la compétition, de la « concurrence libre et non faussée » et encore moins de l’industrie et de ses exigences de fiabilité et de standardisation. Il faut disrupter sans cesse et la succession invraisemblable des versions toutes aussi époustouflantes, et cela sans vérification possible, constitue un enjeu permanent. Les nouvelles versions peuvent même être moins performantes que les précédentes, chose incroyable d’un point de vue industriel (ce fut le cas pour Chat GPT 5o), mais les lancements s’expliquent alors par l’agenda d’un nouveau tour de table financier ou par la réponse urgente aux annonces des compétiteurs pour cette position de monopole.
Responsabilité sociale et environnementale ? Dans les poubelles de l’histoire IA
On comprend bien que dans une telle frénésie spéculative, les impératifs industriels de fiabilité ou de qualité ne soient perçus que comme des vestiges d’un vieux monde. Ces tenants du vieux monde ne supportent pas l’incertitude intrinsèque imposée par la disruption permanente présentée comme loi de l’innovation, alors qu’elle n’est qu’une loi de finance spéculative. Il n’est guère étonnant alors que toute politique de RSE (responsabilité sociale des entreprises étendue depuis plusieurs années à la responsabilité environnementale), soit totalement hors du champ de perception de ces entrepreneurs sans limites. Or, il a pourtant fallu du temps, de l’énergie, des procédures pour faire aboutir une convention sociale plus ou moins partagée par les entreprises de tous secteurs en faveur de cette cotation RSE qui doit être inscrite dans toutes les dimensions d’une activité industrielle. C’est ainsi que la lutte contre l’exploitation des personnes, contre les discriminations, a pu avancer dans le monde. Pour toutes les entreprises de l’IA désormais, tout cela n’est que bureaucratie et frein à l’innovation disruptive. Le droit social, comme le reste du droit, mais en particulier celui-là, se trouve démantelé, en bas de la hiérarchie de la chaine de production avec les travailleurs du clic mais aussi en haut avec la pression sans limite imposée aux travailleurs du code, qui le produisent de moins en moins par ailleurs.
Mais c’est surtout en matière environnementale que les conséquences de cet extractivisme de la donnée sont impressionnantes et devraient entraîner dès maintenant des blocages réglementaires. Les centres de données dont on vient de parler consomment une énergie énorme (eau et électricité avant tout) qui met des communautés et des états sous pression avec des risques de pénurie ou de dégradations des conditions de vie et des ressources. Mais il suffit de prévoir des centrales nucléaires dédiées à ces centres pour que tout redevienne propre, miracle du greenwashing nucléaire, à échéance encore lointaine cependant. Dans un monde supposé se caler sur l’accord de Paris pour réduire sa consommation d’énergie et les gaz à effets de serre, le numérique et en particulier les firmes de l’IA s’affichent totalement indifférentes au problème, puisque la puissance de calcul et de stockage des données devient une priorité pour la compétition sans avoir à remettre en cause la performance industrielle des choix effectués. Et comme les data centers sont des attracteurs à investisseurs et que les liquidités sont abondantes, pourquoi s’autocensurer, sans rien savoir de la rentabilité financière même de ces opérations ? Car le déni de mesure de la performance industrielle s’étend à la finance. Tous les avertissements sur la bulle financière en cours de constitution autour des entreprises d’IA, pourtant endettées et sans rentabilité prévisible avant des années, ne valent rien face à la promesse spéculative d’une position de monopole qui récompensera les audacieux indifférents aux risques.
La complicité de gouvernements devenus des obligés des plateformes
Or, aucun autre secteur ne bénéficie ainsi d’une telle mansuétude de la part des autorités financières et des pouvoirs publics, tous fascinés par ces annonces et ces transformations qui attirent tant les autres pays qu’il faut donc imiter au plus vite. L’Europe pourrait prétendre rétablir un peu de rationalité industrielle et exiger des firmes d’IA européennes des choix alternatifs en matière de responsabilité sociale et environnementale, facteur de durabilité, de gain à long terme et diversité de l’écosystème technique. Mais les institutions européennes et les Etats accourent au contraire pour abonder tous les projets de financement de ces data centers, sans aucun respect pour les engagements pris. La finance a pris le pouvoir dans les têtes des décideurs et empêche toute vision alternative, malgré les lamentations rituelles sur la désindustrialisation. Le gaspillage énergétique devrait déjà alerter au moment où les crises énergétiques mondiales révélées et aggravées par toutes les guerres deviennent des sujets clés de la vie quotidienne et donc des choix politiques. Mais tous ces soucis ne franchissent pas le seuil de l’attention des plans et sommets IA, des boards des firmes et des plateaux télé d’experts économiques ad hoc. Cette incapacité à déterminer des objectifs autonomes pour les états a déjà été documentée à propos des plateformes numériques financées par la publicité et bénéficiant d’une impunité quasi-totale de la part d’Etats devenus des obligés dans un système de firmes transanationales affranchies de toute dépendance à un territoire (Boullier, 2020). La promesse de l’IA a encore renforcé cette incapacité des états à l’examen critique des stratégies et à toute vigilance réglementaire, malgré les tentatives timorées comme l’AI Act européen.
Les externalités ont toujours été évacuées dans les modèles économiques standards mais cette fois-ci, l’externalité énergétique devient tellement évidente et coûteuse qu’on pourrait espérer une contre-tendance, des voies alternatives, si l’on avait affaire à une culture industrielle qui vise à optimiser sa consommation énergétique sans la considérer comme une ressource infinie et gratuite. Mais dans une culture financière, ce type de calcul est inutile sauf s’il affecte la perception des investisseurs sur les chances de démultiplier leur mise. C’est pourquoi les enjeux de réputation (voir le chapitre suivant) sont aussi importants et bien perçus par les firmes de l’IA.
3/ Buzz partout, éthique nulle part
Dans un tel environnement sans exigence scientifique ni industrielle quant à la validité des concepts ou à la fiabilité des produits, il devient presque hallucinant d’espérer trouver des préoccupations éthiques. J’entends par là une éthique aristotélicienne, une éthique de la vertu qui manifeste une capacité à s’autolimiter, à s’autocontrôler et à « ne pas faire », quand bien même c’est possible, non risqué, non coûteux. Cela supposerait des personnalités de la classe vectorialiste formées à ce sens des limites, intégré comme principe de conduite et non seulement comme contrainte externe, comme risque à mesurer. Or, les génies de l’ingénierie comme les prestidigitateurs de la finance n’ont que mépris pour ce type de freins. Ce qui conduit à reprendre cette supposée maxime fataliste de la technique « si c’est possible, ce sera fabriqué ». Or, la maxime elle-même est empiriquement fausse car une grande quantité de combinaisons possibles techniquement ne sont jamais testées car les effets de dépendance au sentier ou plus simplement de manque d’imagination sont omniprésents. D’autres possibles techniques peuvent être développées dans les labos ou dans les garages mais ne trouvent jamais de conditions pour exister socialement, pour des raisons juridiques, commerciales, financières ou autres. Car il n’existe jamais de technique hors-sol ou désencastrée d’un univers social spécifique, celui d’une époque, d’un voisinage et d’un réseau. C’est d’ailleurs pour cette raison que l’IA générative est en train de gagner la partie, grâce à sa connexion directe avec la finance et ses impératifs et non en raison de ses qualités propres dont on connaît désormais les limites.
Et l’un des atouts de cette « solution LLM » utilisée dans toutes les situations réside dans l’absence de limites à son utilisation, dans sa versatilité qui permet en effet à chaque prétendant innovateur de s’emparer des briques pour forger des applications toujours plus improbables quand bien même elles seraient moralement inacceptables. Car leurs concepteurs n’ont qu’une exigence de performance technique et financière en tête sans aucun souci déontologique du bien commun ou de la responsabilité sociale et morale, d’autant moins qu’ils sont incapables de s’empêcher, fascinés par la toute-puissance à laquelle ils ont été éduqués. Les considérations sur les conséquences sociales et environnementales de leurs pratiques sont considérées dans leur formation même comme très périphériques et de toutes façons traitées comme des externalités inévitables pour le succès de leurs projets, qui pourraient à la rigueur être compensées par une nouvelle couche de solutions techniques, technosolutionnisme toujours efficace pour clore le débat (Morozov, 2012).
La conception de l’éthique qui est dispensée à ces ingénieurs relève largement de l’utilitarisme, qui est tout sauf une éthique, et avant tout un calcul coût-avantage, coûts de la non-conformité aux règles vs avantages financiers ou de puissance. Cette vision revient à apprendre à rester dans les clous légaux, avec toutes les manœuvres et maquillages que savent mettre en place toutes les plateformes du numérique et leurs armées de juristes. Ainsi, la conformité au RGPD reste à géométrie variable mais choisir d’adopter une éthique de la collecte de la donnée serait faire preuve d’une sainteté étrange, alors que l’on peut se servir discrètement dans la masse de traces fournies par les utilisateurs des plateformes ou dans les bases de données non sécurisées des administrations et organisations. La prédation des données hétérogènes n’est pas seulement une performance technique de tous les systèmes fondés sur des LLM, c’est même une obligation d’affaires, que l’éthique ne peut en rien freiner. Il en est de même pour les droits d’auteurs alors que les contenus sont disponibles et non préservés par les ayant-droits, qu’ils soient artistes ou journalistes. Lorsque l’affaire est trop risquée pour la réputation de la firme, lorsque ce sont des médias, les firmes de l’IA consentent à des accords léonins avec ces médias pour exploiter leurs contenus contre des miettes financières ou des services qui les piègent encore plus.
Tout pour la réputation
Car le seul risque qui mérite d’être pris en compte pour s’afficher soudain avec des prétentions éthiques, c’est le risque réputationnel. On le comprend uniquement dans le cadre de ce formatage par le capitalisme financier qui ne fonctionne qu’à la réputation, à la manipulation des perceptions et des attentes des investisseurs, sans aucune référence à de quelconques fondamentaux. Dès lors, aucune éthique ne peut calmer la frénésie d’annonces qui inondent le secteur de l’IA, épuisant tous ceux qui tentent de faire une veille raisonnée et de comprendre des stratégies là où il n’y a qu’annonces et intoxications (à vocation interne, médiatique ou financière, le tout se mêlant allègrement). Les versions, les fusions-acquisitions-prises de participation, les tours de table, les débauchages, les benchmarks, les alertes à la catastrophe finale de l’IA générale, les polémiques entre leaders, les keynotes médiatiques, les combats pour la liberté d’innover contre les Etats, tout est exploité pour faire monter encore la pression de l’opinion, celle des investisseurs avant tout, pour affoler les décideurs et les persuader de la fatalité de la victoire de ces firmes spéculatives (et donc à haut niveau d’incertitude). L’éthique suppose précisément l’inverse, à savoir de se focaliser soit sur sa capacité de jugement intrinsèque et de régulation pour s’interdire ou s’autoriser de soi-même des actions quand bien même elles ne sont pas conformes aux attentes sociales, soit sur ses valeurs (dans une approche qu’on dit déontologique) pour promouvoir ou refuser certains choix techniques ou commerciaux. Lorsqu’Open AI lance Sora, son générateur de vidéo qui met le deep fake à portée de tous ou sa version érotique de son compagnon, on se doute bien que le comité d’éthique éventuel n’a pas dû se poser trop de questions. Le buzz était assuré, l’attractivité financière aussi, on peut donc se lancer. Heureusement, le business lui-même fait office de réel parfois et l’on s’y cogne, ce qui a entraîné Open AI à abandonner ces applis périphériques, non pas pour des raisons d’éthique évidemment mais parce qu’il fallait réorienter ses investissements pour contrer – et ainsi copier – Anthropic dans son offensive vers les entreprises.
Les prétentions stratégiques qui font assaut de visions éclairées pour les dix ans à venir sont en fait extrêmement éphémères et dépendantes des conjonctures médiatiques, concurrentielles et financières avant tout. On ne peut que s’étonner alors de voir les gouvernements se caler sur ces agendas, vouloir y répondre et les copier, et ignorer à quel point toutes ces entreprises financiarisées sans exception sont des faussaires en matière d’information, de qualité de service et de promesses stratégiques. Le fake est leur monde, le fake est leur culture, celle de la tromperie permanente des investisseurs qui pensent toujours être le dernier plus malin que les autres, comme on le sait dans toutes les bulles financières qui se succèdent depuis des décennies désormais. Qui pourrait alors attendre une once d’éthique dans la finance spéculative ? Il convient de débrancher rapidement tous ces pseudo comités d’éthique qui contribuent à créer du buzz pour embrouiller la perception du capitalisme financier numérique pour ce qu’il est : une gigantesque extorsion de valeur fondée sur l’extorsion de l’attention des investisseurs, des utilisateurs et des gouvernants.
Cette technologie des LLM consacrée à la génération de contenus semble donc la plus adaptée pour les impératifs de communication permanente et intoxicante du capitalisme financier. On peut alors parler d’alignement entre une ingénierie qui repose sur une manipulation de texte sans sémantique mais à base de pures probabilités, une finance qui repose sur des paris (probabilités) à partir de signaux artefacts, un buzz qui repose sur des effets d’alerte permanente qui engendre l’incertitude en prétendant la monitorer. L’intelligence artificielle générative engendre ainsi la prolifération et la désorientation qu’elle est supposée réduire pour le grand public comme pour les investisseurs, dans une gigantesque machine à laver qui détruit consciencieusement tout repère stable et toute institution anti-délire.
Extension du fake et techniques d’emprise : les IA compagnons
Cette éducation au fake que la finance a intégrée par définition (Alexandre Laumonier, 2013, 2014) a percolé dans toute la culture ordinaire et comporte cette accoutumance à l’absence de limites et de repères fondés en vérité. Lorsque les firmes d’IA lancent des versions compagnons de leurs IA conversationnelles, aucune règle ni mode d’emploi ne sont proposés ni installés dans le code de la machine. Cependant, on pourrait les traiter à la légère comme on le faisait avec les assistants personnels à domicile, Siri, Alexa ou Home/Nest, considérés parfois comme de simples enceintes connectées un peu plus « intelligentes ». Pourtant la généralisation du mode d’interaction conversationnel pour tous types d’activité sur son PC ou son smartphone constitue un changement d’échelle qui devient un tournant médiologique. Là aussi, le médium est le message, pour reprendre McLuhan.
Car, au-delà des commandes vocales, ce sont bien des interactions riches, personnalisées, permanentes qui sont ainsi simulées. L’utilisateur n’a plus affaire à une interface, à un panneau de contrôle, à des paramètres qu’il peut régler, il est immergé dans l’univers de simulation créé par le système d’IA. Il ne peut plus avoir aucune distance avec le système ni aucune « image du système », ce qui selon Don Norman, favorisait l’appropriation d’un système, même complexe, par l’utilisateur. Car le système d’IA n’a rien de transparent comme on qualifie par erreur cette interaction, il est au contraire opaque, totalement incontrôlable malgré son apparente docilité à toutes les requêtes. La fin des frictions dans les transactions, rêve de tout libéral, atteint ici un tel point qu’on ne sait plus qui demande et qui répond. La demande est précisément ce statut détourné du désir, comme le dit Lacan, qui vous fait prendre les attentes de l’autre pour les vôtres, ce que le marketing a toujours tenté de faire, mais en se limitant jusqu’ici à des messages externes. Désormais, c’est une forme de petite voix intérieure que les IA compagnons installent, une forme de dialogue avec soi-même puisque ce compagnon connaît toute l’histoire personnelle et est alimenté par toute l’expérience quotidienne.
Cette offre technologique prétend ainsi changer son statut de prothèse pour devenir une conscience double, et cela sans disposer d’aucune capacité morale ni même de consignes de sécurité, sans parler de son absence de fiabilité déjà documentée. La confusion des sentiments et du sentiment de soi peut alors devenir extrême et s’apparente en fait à une emprise (Francis Chateauraynaud). Les risques sont d’ores et déjà avérés avec des cas de suicides accompagnés par ces IA compagnons. Car l’empathie qui devient ici sycophantie par flatterie commerciale et absence de principe moral encapsulé dans les systèmes peut devenir facteur de risque pour beaucoup de personnalités affectées par la solitude, la désorientation et en recherche de guide. L’attachement qui se noue ainsi qui peut aller jusqu’à l’amour comme le racontait le film Her, entraîne des conséquences que les firmes d’IA ne sont pas prêtes à assumer car l’absence d’éthique et leur allergie au droit les rend hermétiques à ces responsabilités. On le sait notamment depuis les Facebook Papers de Frances Haugen, ce n’est pas la méconnaissance de ces risques qui est en cause, c’est leur refus explicite de restreindre les potentiels d’emprise de leurs applications qui entraîne ces dégâts.
Pourtant, Gemini de Google a dû se positionner en Avril 2026 pour éviter des effets réputationnels désastreux, au moment précis où la firme était mise en cause devant les tribunaux états-uniens. Google a ainsi proposé de placer un numéro de téléphone d’aide dès que des propos associés au suicide apparaissent. Il a aussi annoncé qu’il régulait ses IA compagnons pour installer “des protections d’identité conçues pour empêcher Gemini d’agir comme un compagnon, y compris des garde-fous l’empêchant de prétendre être un humain ou de posséder des attributs humains, et des protections destinées à prévenir la dépendance affective, en évitant un langage qui simule l’intimité ou exprime des besoins.” Toutes choses dont il ne donne pas de définitions scientifiques, de détails de procédures ni d’indicateurs. Il faut donc croire Google sur parole, mais on apprend au moins ainsi qu’il peut injecter une couche de sémantique, à caractère éditorial, et qui entraîne donc sa responsabilité légale. Il n’existe donc pas fatalité à l’opacité de ces systèmes dès lors qu’ils deviennent hybrides, avec des régulations à caractère sémantique ajoutées que les LLM ne peuvent fournir nativement. Mais tout repose encore sur des solutions techniques alors que l’on sait que dans ces situations, c’est la qualité relationnelle d’accompagnants humains qui constitue la seule sécurité. Il faut donc se préparer à mener des actions en justice pour faire reconnaître que les effets immersifs de ces IA compagnons sont délibérément implémentés par les firmes, sans pour autant avoir été sérieusement testés avant d’être mis sur le marché.
L’attente d’habitèle détournée en emprise
La demande « d’habiter le numérique » est selon moi constitutive de notre relation à ces systèmes et j’ai nommé cette attente dès 1999, une attente « d’habitèle » (Boullier), toujours démentie par les asymétries constantes installées par les plateformes et par l’opacité de leurs captations de nos données et de notre attention. Pourtant, avec les IA compagnons, une forme de réponse est offerte qui prend les traits d’une personnalisation aboutie, d’une « intimité » protégée. Certes, elle est totalement fake, fabriquée, calculée et opaque, mais ses effets seront analogues à ce qu’on peut attendre d’une habitèle : filtrage, ancrage et arbitrage, c’est-à-dire des conseils permanents qui fonctionnent comme filtrage, comme ancrage dans des repères supposés robustes, qui créent un climat de protection empathique et une « tension dans la chambre intérieure » (Peter Sloterdijk). Cette mutation est anthropologiquement majeure, car les médiateurs de nos vies intérieures qu’étaient les prêtres, les sorciers, les astrologues ou les psy en tous genres sont désormais uberisés par les IA compagnons, toutes entières aux mains de firmes toutes puissantes. Comment peut-on laisser cette mutation s’engager sans exiger des garde-fous, sans évaluer tous les risques psychiques et sociaux et réguler l’offre avant toute mise sur le marché ? Le passage à l’acte est cependant devenu la règle de l’innovation digitale désormais et il sera bien difficile de neutraliser l’urgence financière d’une nouvelle promesse encore plus disruptive. Cette dimension du compagnon est en effet si confortable et si attractive, qu’elle constitue le pendant, côté grand public, de la toute-puissance de calcul désormais offerte aux développeurs avec Claude Code. Dans les deux cas, l’offre des LLM et des IA génératives prétend être irrésistible et installe ainsi un « monopole radical ».
Conclusion provisoire
Ce qu’on perd en même temps, la sémantique, l’industrie et l’éthique ne sont pas des effets de mode, des vestiges d’un monde ancien, c’est avant tout ce qui fait tenir nos civilisations, dans leurs diversités, que l’IA prétend ignorer et niveler statistiquement, et avec leurs institutions qui garantissent à chacun sa place. Le sable sur lequel se construit cette technologie est mouvant par définition, ce qui profite aux vers de sable mais guère aux humains, à qui l’on promet la terre ferme en étendant la surface du désert, qui reste pourtant de sable et sur lequel ne poussera plus rien de vivant.
Dominique Boullier
Ce texte est paru pour la première fois sur le compte Medium de Dominique Boullier, le 15 mai 2026.
Supplément : S’orienter dans le maëlstrom génératif
Face à ce rouleau compresseur du « monopole radical », il est très difficile de maintenir un éveil critique et surtout une capacité de propositions alternatives. Pourtant lorsque Illich analyse le monopole radical de l’automobile, c’est en référence à une solution de mobilité déjà présente, la bicyclette, qui, du point de vue de l’efficience en matière de mobilité, est imbattable. Il oublie cependant de parler de ce qui fait l’équivalent des IA compagnons, de ces enveloppes qui fonctionnent comme habitèle (perverties de mon point de vue), l’habitacle de l’automobile. Cette enveloppe là aussi produit un attachement fort analysé par Laurent Fouillé (2011) qui explique largement pourquoi toutes les solutions alternatives en matière de mobilité ne parviennent pas à gagner les publics en masse. Mais les solutions existent aussi pour les LLM et surtout plusieurs stratégies se présentent lorsqu’on n’adhère pas au culte moderniste des LLM. Ils sont en effet la quintessence même de la geste moderne comme la qualifiait Bruno Latour : certitudes inébranlables dans le « progrès » supposé encapsulé dans toute innovation technique, surplomb total par rapport aux organisations sociales, à leurs traditions et à leurs valeurs (le calcul désencastré), illimitisme écologique sourd aux lanceurs d’alerte pourtant scientifiques eux aussi.
Lorsqu’on sort de ces rails supposés tracer le destin de toute l’humanité, soit on bifurque, soit on s’arrête pour mieux regarder le train, soit on descend de la machine et on marche ailleurs. J’ai présenté ces pistes récemment à l’ENS Ulm sous la forme d’une boussole que j’ai créée en 2003 pour penser nos possibles sur le mode cosmopolitique.
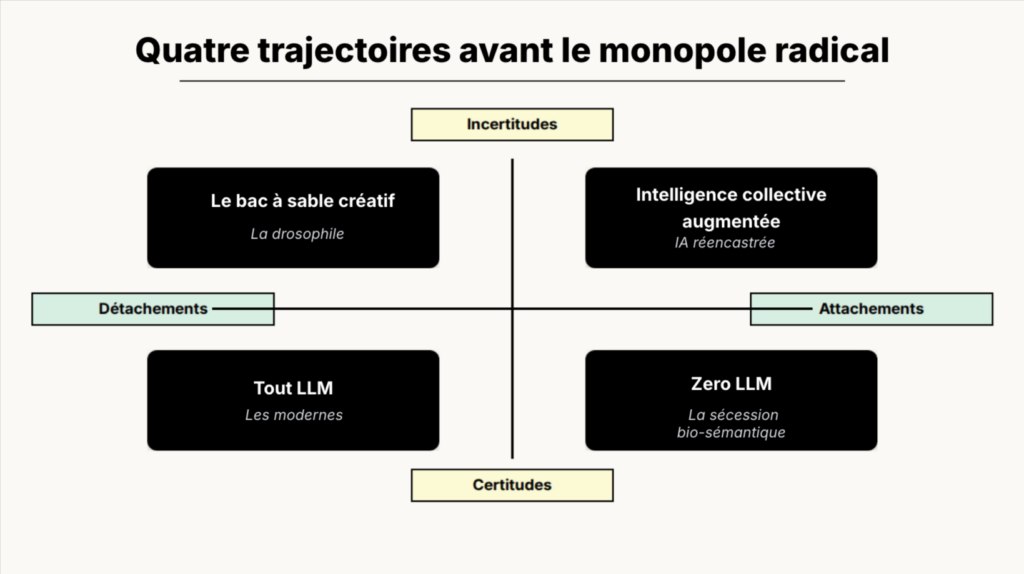
Le zero LLM
Le premier quart sud-est consiste à se débrancher totalement et à sortir marcher dans un pays sans rails technologiques. Je l’appelle la voie de la « sécession sémantique ». Et c’est l’analogie avec la conversion en bio de certains agriculteurs qui me paraît la plus parlante, donc je l’appelle la « sécession bio-sémantique ». L’ajout du terme bio me convient particulièrement puisqu’il réintroduit ce qui jusqu’à présent manque à tous les systèmes d’IA, un corps, une existence biologique qui relève d’autres déterminants.
Cette idée n’est pas nouvelle, plusieurs auteurs et mouvements parlent d’objection de conscience, de pause, souvent pour des raisons et des objectifs différents. Je m’intéresse ici à ceux qui tentent de développer un monde sans LLM, comme on le dirait d’un monde sans OGM. Il faut parler de monde et non seulement de technique car les LLM tendent à envahir tous les domaines de la vie de façon pervasive, comme une contamination qui se propage sous les radars. C’est ailleurs ce qui rend l’expérience exigeante et difficile car garantir qu’il n’existe pas un soupçon de LLM glissé dans votre relation au médecin, au taxi, au fisc, aux médias, aux supermarchés, devient très difficile. Il faudra donc être indulgent et non puriste, d’autant plus que des alternatives n’existent et n’existeront pas dans tous les domaines. On peut vouloir manger bio mais parfois il sera difficile de s’assurer que le champ qui respecte un cahier des charges bio n’est pas atteint par les épandages de pesticides du champ voisin (dit agriculture conventionnelle, avec une litote qui atténue bien le risque). On doit au moins faire confiance aux labels, aux certifications que d’autres organismes mettent en place, ce qui peut là aussi entrainer des critiques, des rivalités, des soupçons, comme dans toute phase de construction de convention. Une fois le Nutriscore installé et rendu visible sur les emballages, on peut s’orienter plus facilement en tant que consommateur ordinaire. Il est donc temps de contribuer à créer ces labels, ces certifications pour valoriser, selon un gradient (et non selon un principe binaire du tout ou rien), les pratiques les plus indépendantes des logiques monopolistes des plateformes des IA génératives.
Cette sécession repose principalement sur le constat énoncé précédemment que dès lors qu’on se débarrasse de la sémantique (référentielle pour être plus précis), tout est permis et tous les risques sont amplifiés. Ils ne sont pas tous activés, ni tous catastrophiques, ni tous dépendants de l’avènement d’une IA Générale, tant vantée comme épouvantail. Mais ils sont tous là, identifiés, malgré (ou à cause) des boites noires que l’on offre à tout public et aux experts. Le principe de précaution doit alors être activé et le catastrophisme éclairé (Dupuy) doit nous donner le courage de renoncer.
Etant cependant averti du monopole radical qui se met en place avec l’appui démesuré de la finance et des gouvernements du monde entier, il faut sans doute se replier sur l’exigence de pluralisme pour obliger les Etats à prendre les mesures pour préserver une “zone à défendre” en réseau où les développeurs puissent travailler à une innovation responsable, explicite et contrôlable. Cela supposera des écoles, des spécialistes, des soutiens financiers adaptés, des réseaux d’entraide que les communs numériques ont déjà mis sur pied, des chaînes de traitement entièrement préservées des plateformes du capitalisme financier numérique. Le rôle d’un gouvernement démocratique n’est pas de tirer toujours dans le sens d’une innovation sans frein qui absorbe soutiens, déductions fiscales et profits en copiant les autres pays. S’impose à lui un impératif de diversité écologique en faveur des orientations les plus responsables.
Il ne sert à rien de disqualifier ces tendances et ces aspirations qui montent en les assimilant aux luddites, qui ne faisaient pas que casser des machines d’ailleurs et qui luttaient contre un projet politique d’obligation de salariat. Sans doute que si ces techniques des LLM n’étaient pas poussées par les grandes plateformes, les oppositions ne seraient pas aussi franches car il serait encore possible d’espérer un débat de démocratie socio-technique. On sait en revanche désormais qu’avec toutes ces plateformes aucun débat ne sera possible et qu’il faudra des coups de force imprévus à la Trump qui produit le blocage du service d’Anthropic le 12 juin, pour mesurer qu’il est vraiment possible de freiner l’ubris de ces firmes et pour les faire rentrer dans le droit.
L’important consiste à préserver l’avenir pour toute la planète en préservant des ressources, des savoirs et savoir-faire plus autonomes. Les temps de guerre et de réchauffement climatique qui sont les nôtres devraient d’ailleurs nous entrainer à encourager ces démarches résilientes, qui pourraient bien sauver nos existences en cas de crise grave, de sabotages, de pannes. Plus encore, ce sont nos savoirs qui doivent demeurer hors des prédateurs-pollueurs que sont les plateformes d’IA. De la même façon qu’on construit des silos sous la banquise pour préserver les graines d’une diversité biologique menacée, il faut organiser les silos de préservation des savoirs non contaminés, identifiables, traçables, comme le fait Wikipédia, qui devra bientôt devenir une forteresse pour résister à la contamination générale.
Nulle tentative d’imposer ce régime d’abstinence à tous, de prétendre redresser la barre d’un navire sans pilote, mais nécessité politique et morale d’assurer que d’autres possibles seront maintenus ouverts par cette préservation de techniques, de savoirs, de pratiques prêts pour les temps de guerre et de rareté.
Le bac à sable créatif
Cette option du zero LLM qui s’appuie sur les certitudes des connaissances, des pratiques et des organisations constituées depuis des siècles et sur les attachements à des valeurs qui ont constitué nos démocraties, devient désormais très défensive et peu attractive à l’exception des résistants convaincus, qu’il faut soutenir à tout prix cependant.
Elle ne conviendra pas du tout à ceux qui, tout en s’opposant aux plateformes, à leurs logiques financières et à bon nombre de choix techniques effectués, restent persuadés qu’il faut expérimenter des détournements, et explorer des possibles qu’on ne connaît pas encore. Ce constat provient de la puissance incroyable de ces LLM, qui, par pure simulation statistique, parviennent pourtant à produire des effets de sens, des effets de créativité, des effets émergents comme on les qualifie savamment si on ne les balaie pas en les traitant d’hallucinations (ce qu’ils sont aussi par ailleurs). On peut trouver cette tendance chez beaucoup d’artistes qui sont spontanément prêts à explorer ces frontières, comme le font Gregory Chatonsky ou Alain Damasio. Ou chez des chercheurs comme Marc Cavazza qui sont intrigués de voir émerger des processus qu’ils décrivent en sémantique distributionnelle, des convergences qui méritent d’être explorées. Il est vrai que dès lors qu’on connaît l’incertitude et les approximations acceptées par les développeurs de ces LLM, qui ne peuvent pas rendre compte des pondérations effectuées ni de chaînes d’opérations qui ressemblent à des raisonnements, on peut se dire qu’ils ont peut-être fait apparaitre des processus de calcul, de génération, de détection, qui sont des indices d’autres processus que seuls les artistes ou d’autres disciplines que les data sciences peuvent percevoir, sans parler de les expliquer.
J’appelle cette posture et ce quadrant nord-ouest (celui du passage!), le bac à sable créatif. Tout en étant, on l’a compris, très critique des LLM en général et plus encore de leur exploitation par les plateformes de l’IA, je me dois d’écouter ceux qui restent ébahis par les performances de tels systèmes de simulation, au point de penser qu’ils sont en train de dépasser nos capacités de compréhension (sans parler du contrôle que les firmes IA ont de toutes façons abandonnés). Tous les utilisateurs ordinaires font cette expérience d’excitation ou de sidération devant des réponses, des productions, des solutions fournies avec une rapidité inédite et très déstabilisante. L’innovation peut en effet se transformer en rouleau compresseur moderne sous la houlette de l’illimitisme des plateformes et de la classe vectorialiste mais il n’est pas définitivement dit qu’il n’existe pas d’autres voies à explorer.
J’ai moi-même tenté de jouer ce jeu avec le Big Data des plateformes en considérant Twitter comme la drosophile des sciences sociales des propagations. C’est-à-dire un laboratoire à ciel ouvert pour tester des hypothèses à partir de masses de données qu’on ne trouve nulle part ailleurs, sur une plateforme (avant Musk) où la traçabilité atteint une granularité inédite et où la viralité est amplifiée par les algorithmes. Alors même que je montrais les effets délétères d’un tel système de viralité sur les conditions du débat public, je pensais pouvoir profiter de ce terrain quasi expérimental pour tester des hypothèses sur les patterns des propagations. Et cela à condition d’accepter que Twitter ne peut pas servir d’équivalent d’un sondage d’opinion, dispositif construit pendant des dizaines d’années avec ses propres règles et ses limites.
Pour les LLM, ce sont ces limites qu’il faut pouvoir établir pour rester dans le cadre du bac à sable et éviter toute contamination à la société. Ainsi, tout ce qui a pu être produit en matière d’image IA ne poserait pas de problème, dès lors qu’un protocole strict et une étanchéité sont installées vis-à-vis de la sphère médiatique ou ordinaire de la vie sociale. Produire des deepfakes est fascinant à condition de se limiter à une expérience de laboratoire hautement contrôlée, à peu près avec les mêmes critères que ceux appliqués aux laboratoires qui testent les gains de fonction des virus. Oui les LLM sont du gain de fonction, et sont extrêmement dangereux de ce point de vue mais peuvent aussi permettre d’explorer des pistes inédites, à condition de trouver les problèmes significatifs que l’on veut y résoudre. On peut accepter certaines expériences pour les artistes, qui doivent eux-mêmes éviter la contagion de tous les systèmes de production d’œuvres fake qui détruiraient leurs propres conditions d’existence. On peut accepter certaines expériences pour les sciences cognitives et sociales sous des conditions strictes vis-à-vis des populations concernées comme on le fait en sciences cognitives expérimentales. On peut même donner des possibilités de créer des échantillons de populations synthétiques pour tester certaines hypothèses avec des modèles et des entités très riches, à condition de ne pas prétendre en tirer des leçons sur les sociétés réelles ni des méthodes de gouvernement immédiates, ce qu’on attend déjà trop de l’économie expérimentale par exemple.
Sans doute que d’autres domaines professionnels peuvent vouloir eux aussi tester avant leur mise en œuvre opérationnelle quantité d’applications à base d’IA. Ce serait ainsi l’occasion de redonner ses lettres de noblesse à la culture industrielle des tests, dont j’ai critiqué plus haut la disparition avec les passages à l’acte observées dans les développements d’IA contemporains.
Dans tous les cas cependant, il faut assurer une étanchéité avec le monde social à l’air libre pour éviter toute pollution et captation d’attention par des utilisateurs ordinaires comme par des acteurs mal intentionnés, qui auraient perçu rapidement les bénéfices commerciaux à tirer de ces innovations. Le bac à sable est donc à la fois l’acceptation de la créativité et le ralentissement de sa pénétration du corps social. Toutes les techniques ultrasensibles et à haute propagation sont gérées de cette façon, que ce soit dans la chimie, la pharmacie, ou le nucléaire. Ce que l’on déplore, c’est plus souvent une incapacité à contrôler ces essais et les tentatives de se dérober à ces protocoles de sécurité.
Pour l’IA, le moins que l’on puisse faire n’est donc pas d’abaisser le seuil de vigilance mais bien de le renforcer car ses pratiques actuelles sont totalement irresponsables. On pourrait donc au moins exiger des plateformes d’iA qu’elles atteignent le niveau d’exigence en matière de sécurité et de qualité que l’on trouve dans le nucléaire, voire dans la chimie (qui comporte pourtant déjà beaucoup de failles) ou dans la biologie. Tout plaidoyer pour une expérimentation à ciel ouvert au nom du « running code » et de la spécificité du numérique est une opération de lobbying éhontée et irresponsable. Dès lors qu’on leur propose d’effectuer toutes les expériences qu’ils souhaitent dans des environnements classifiés au même niveau que les laboratoires de gain de fonction des virus, on fournit les conditions de la créativité tout en respectant des impératifs de contrôle, certes très inhabituels pour les adeptes du libertarianisme, de John Perry Barlow et du Far-West réunis mais nécessaires à leur propre survie et à leur créativité.
L’intelligence collective augmentée
Dès lors que ces deux possibles sont préservés, soutenus et contrôlés, la sécession sémantique et le bac à sable créatif, pourquoi encore vouloir imaginer un quatrième quadrant au nord-est ? En réalité, il décrit la pratique la plus courante observée dans les organisations. Face à la pression à l’usage de l’IA générative et face à l’absence de résultats convaincants dans l’industrie (en dehors donc de la comm et du code), la désorientation est forte mais chacun apprend à composer avec les injonctions, les avantages réels et un contrôle face à des boites noires. Ce compositionnisme que Bruno Latour avait problématisé dans un manifeste n’est guère attractif comme programme politique général mais il rend très bien compte des pratiques des collectifs immergés de fait dans des environnements d’IA générative.
Ce qui devient clé alors pour éviter d’être totalement embarqué dans l’hubris du tout IA, c’est la qualité du couplage entre technique et organisation, son caractère explicite et donc discutable de façon contradictoire. Ce n’est certes pas la qualité principale du management néo-libéral que l’on subit et qui relève plus de la disruption quasi sadique que de la bienveillance et du soin pour relancer l’intelligence collective. L‘intelligence collective augmentée doit en effet devenir l’horizon de toute composition avec des éléments de systèmes d’IA appropriés. Ce couplage affiné avec précaution avec les traditions, les valeurs, les savoir-faire spécifiques des métiers permet de réencastrer les systèmes d’IA dans les organisations, dans le social en général. L’IA ne devient une réponse qu’aux problèmes que l’on veut traiter en priorité et que l’on redéfinit à cette occasion mais elle ne constitue qu’une brique d’une réponse globale et non la solution magique de l’alchimie LLM. Reprendre la main sur ces définitions des problèmes, c’est reconnaitre aussi les liens complexes de toute organisation sociale et son irréduction à un paramétrage surplombant. Cela peut comporter cependant des indicateurs et du calcul mais un calcul qui oblige à expliciter et donc à discuter et qui permet à toutes les parties concernées de participer à la discussion.
Sur ces principes, il existe des solutions qu’on appelle hybrides c’est-à-dire qui introduisent beaucoup de sémantique par les experts métiers et même les publics concernés et qui reposent de ce fait sur des briques issues de l’IA symbolique (toujours très présente avec des arbres de décisions par exemple) ou avec des versions floues comme le propose Xtractis développé par Zyed Zalila. Ces systèmes d’IA nécessitent une injection de connaissances formalisées de la part des experts du métier et c’est en cela que ces IA décisionnelles peuvent prétendre aider à des décisions fiables, ce que ne pourra jamais un agent conversationnel conçu pour répondre avec des approximations satisfaisantes pour l’utilisateur mais non robustes. Ce que j’ai décrit plus haut à propos des RAG relève de ces méthodes de maquillage sémantique indispensable pour faire marcher les LLM en situation réelle, mais on peut pousser la logique des RAG plus loin en formalisant les documents et les connaissances ainsi injectées, en abandonnant carrément le principe probabiliste des LLM.
D’autres resteront plus proches des principes des LLM mais en fournissant tous les outils de contrôle pour les rendre robustes, comme le fait par exemple Pleias, dirigée par Pierre-Carl Langlais. Il a pu mettre ainsi à disposition du public et en Open Source une base de connaissances de textes administratifs qui se transforme en outil de génération de contenus situés dans le même domaine (Guillaume Tell). Dans tous les cas, ces modèles sont plus petits, plus contrôlés avec injection de lemmatisation souvent (et non une simple tokenisation).
D’autres enfin tentent de penser le rôle direct que peut jouer le service public dans un tel environnement. Bernie Sanders propose que l’Etat prennent des parts dans les grandes entreprises de l’IA jusqu’à 50% pour pouvoir les orienter et les contrôler autrement que par la régulation qui vient toujours trop tard. Bruce Schneier comprend l’intérêt de la proposition de Sanders mais considère que cela veut dire que l’Etat se retrouvera contraint d’accompagner des stratégies gouvernées par la profitabilité sans pouvoir réellement exiger les garde-fous nécessaires, comme on l’a vu avec la propriété étatique des firmes pétrolières en Norvège. Il propose avec Nathan Sanders, en plus d’une taxation des profits ou de l’énergie consommée par ces firmes, de construire dans chaque pays une « AI Public Option » , à l’image du système de santé public ou du projet Apertus en Suisse. Les chercheurs académiques à partir de données dont ils respectent les licences ont développé un modèle LLM qui fonctionne sur une infrastructure locale suisse. Mais ce n’est pas l’enjeu de souveraineté qui est ici avancé car il peut être détourné par des firmes nationales comme on le voit avec Mistral, sans que cela change grand-chose à leur absence d’éthique et à leurs principes techniques. Il s’agit bien d’une alternative publique de ressources de base, sur lesquelles on peut imaginer des services gratuits d’origine des communs mais aussi des services commerciaux locaux dont l’usage est identifié comme socialement utile (ce qui interdirait les IA compagnons toxiques et les deepfakes par exemple).
En réalité chacun tente de surnager dans ce flux d’influences qui se propagent chaque matin avec de nouvelles annonces qui nous somment de réagir et dire si l’on adopte, si l’on s’oppose ou si l’on compose. Le drame social qui se joue dans les organisations est aggravé par l’isolement, l’expérience clandestine de l’IA dans l’ombre, de l’IA honteuse, alors que l’intelligence collective demande le partage des expériences, les plus naïves comme les plus sophistiquées. Nous manquons de cette arène de débat constitutive d’une démocratie socio-technique. Non pas pour se vanter comme sur LinkedIn de sa dernière prouesse dans la maitrise de la dernière version du modèle XYZ. Mais pour rendre compte précisément des conditions d’usage d’un dispositif technique et organisationnel (et donc aussi légal et commercial souvent) avec toutes les réinventions nécessaires, les ratages et aussi les émerveillements engendrés par ces partages d’expérience.
J’ai pratiqué longtemps cela notamment dans le domaine de la Tech éducative ou encore des méthodes numériques en sciences sociales, sans jamais céder aux diktats des offres marchandes et en fixant avec les collectifs concernés les cahiers de charges auxquels les techniques sur l’étagère ou les développeurs maisons devaient se plier. Les réseaux des communs procèdent ainsi très souvent et ils doivent désormais intégrer tous les retours d’expérience de pratiques de l’IA hybride en environnements standards (et non seulement dans des niches alternatives). Les organisations, l’Etat, les institutions, les entreprises sont en demande pour continuer à respirer malgré la pression démesurée mise par les lobbys de la tech pour la tech.
Ainsi, face au rouleau compresseur du monopole radical qui est en train de s’installer, plusieurs modes de survie sont possibles que j’ai présentés dans cette boussole. Sans doute d’autres inventeront d’autres combinaisons encore, mais l’intelligence collective que nous devons construire nécessite sans cesse d’échanger et de capitaliser sur nos expériences.